ECCV 2026
ECCV 2026To appear
Gripper-aware Vision-Language-Action Models
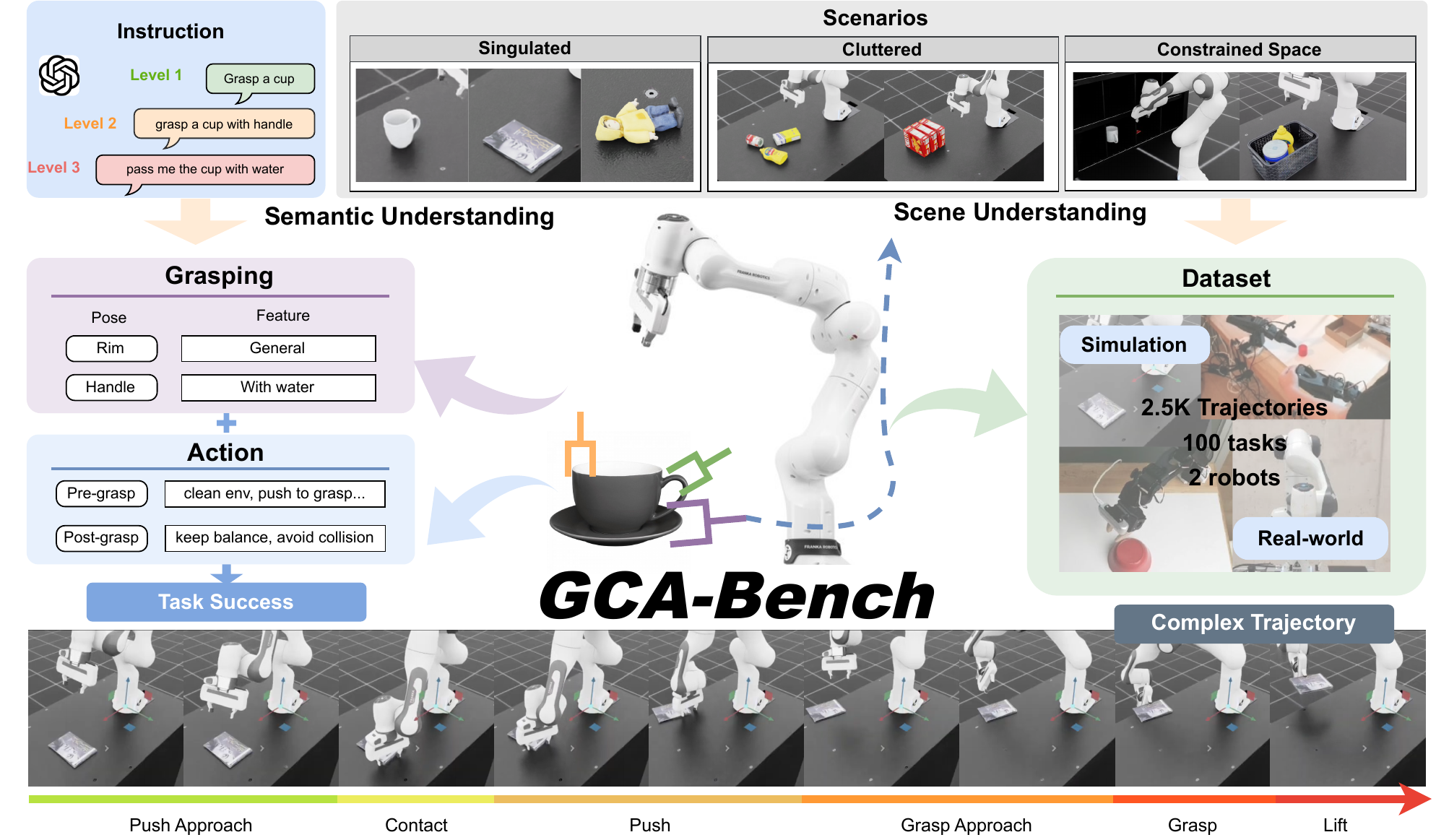
We introduce MiGA, a dataset of 103,000 demonstrations across five gripper types, and GVLA, a gripper-conditioned VLA framework combining multi-gripper tokenization with a dual Mixture-of-Adapters. Experiments in simulation and on real robots demonstrate improved gripper-aware strategy learning, generalization, and cross-gripper transfer.